LangChain4j Retrieval-Augmented Generation (RAG) Tutorial
In this article, we will explore the following:
- Understand the need for Retrieval-Augmented Generation (RAG).
- Understand EmbeddingModel, EmbeddingStore, DocumentLoaders, EmbeddingStoreIngestor.
- Working with different EmbeddingModels and EmbeddingStores.
- Ingesting data into EmbeddingStore.
- Querying LLMs with data from EmbeddingStore.
Sample Code Repository
You can find the sample code for this article in the GitHub repository
LangChain4j Tutorial Series
You can check out the other articles in this series:
Understand the need for Retrieval-Augmented Generation (RAG)
In the previous articles, we have seen how to ask questions and get responses from the AI models. But while building AI powered applications for your business, the AI models don’t have the context of your business data.
Your business might store structured data in relational databases, unstructured data in NoSQL databases, or even in files. You will be able to effectively query relational databases using SQL, NoSQL databases using their query languages. You can also use full-text search engines like Elasticsearch, Solr, etc., to query unstructured data.
However, you might want to retrieve data using natural language with semantic meaning.
For example, “I love Java programming language” and “Java is always my go-to language” have the same semantic meaning, but uses different words. Trying to retrieve data using the exact words might not be effective.
This is where Embeddings comes into play. Embeddings are vector representations of words, sentences, or documents. You can use these embeddings to retrieve data using natural language.
You can convert your structured and unstructured data into embeddings and store them in an EmbeddingStore. You can then query the EmbeddingStore using natural language and retrieve relevant data. Then, you can query the AI models passing along the relevant data to get the responses.
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a LLM, by using additional knowledge base in addition to its training data before generating a response.
Understand EmbeddingModel, EmbeddingStore, EmbeddingStoreIngestor
First, let us understand the various components involved in RAG.
EmbeddingModel
An EmbeddingModel is a model that can convert words, sentences, or documents into embeddings. An embedding is a vector representation of words, sentences, or documents.
For example, A word “Apple” might be represented as a vector [0.1, 0.2, 0.3, 0.4, 0.5].
A sentence “I love Apple” might be represented as a vector [0.1, 10.3, -10.2, 90.3, 2.4, -0.5].
LangChain4j provides an interface EmbeddingModel and support various implementations:
- AllMiniLmL6V2EmbeddingModel: An embedding model that runs within your Java application’s process
- OpenAiEmbeddingModel: Represents an OpenAI embedding model
- AzureOpenAiEmbeddingModel: Represents an Azure OpenAI embedding model
- OllamaEmbeddingModel: Represents any of the Ollama supported models embedding model
- VertexAiEmbeddingModel: Represents a Google’s Vertex AI embedding model
- HuggingFaceEmbeddingModel: Represents a HuggingFace embedding models
We can create an instance of the EmbeddingModel as follows:
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
// or
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.withApiKey("demo");
// or
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama2")
.build();
EmbeddingStore
An EmbeddingStore is a datastore that can store embeddings of words, sentences, or documents. There are various Vector databases available in the market like Neo4j, ElasticSearch, Pgvector, Redis, Chroma, Milvus, etc., that can store embeddings.
LangChain4j provides an interface EmbeddingStore and supports various implementations:
- InMemoryEmbeddingStore
- Neo4jEmbeddingStore
- OpenSearchEmbeddingStore
- ChromaEmbeddingStore
- PineconeEmbeddingStore
- MilvusContainer
- and more…
You can create an instance of the EmbeddingStore as follows:
EmbeddingStore embeddingStore = new InMemoryEmbeddingStore();
// or
EmbeddingStore embeddingStore = ChromaEmbeddingStore.builder()
.baseUrl("http://localhost:8000")
.collectionName("my-collection")
.build();
// similarly, you can use any other implementation
DocumentLoaders
A DocumentLoader is a component that can load data from various sources like files, URLs, etc., into a Document.
LangChain4j provides various DocumentLoader implementations:
- FileSystemDocumentLoader: Loads data from files into a Document
- UrlDocumentLoader: Loads data from URLs into a Document
Path path = Paths.get("/path/to/some/file.txt");
Document document = FileSystemDocumentLoader.loadDocument(path, new TextDocumentParser());
You can load a Document from Web URLs as follows:
URL url = new URL("https://www.sivalabs.in/about-me/");
Document htmlDocument = UrlDocumentLoader.load(url, new TextDocumentParser());
HtmlTextExtractor transformer = new HtmlTextExtractor(null, null, true);
Document document = transformer.transform(htmlDocument);
EmbeddingStoreIngestor
An EmbeddingStoreIngestor is a component that can ingest data into the EmbeddingStore.
We can convert text data into embeddings using the EmbeddingModel and store it in an EmbeddingStore as follows:
TextSegment segment = TextSegment.from("your text goes here");
Embedding embedding = embeddingModel.embed(segment).content();
embeddingStore.add(embedding, segment);
Our data could be in various file formats like TXT, CSV, PDF, Web Pages, etc. We can load the data from files into Documents, split the documents into text segments, convert the text segments into embeddings, and store them in the EmbeddingStore.
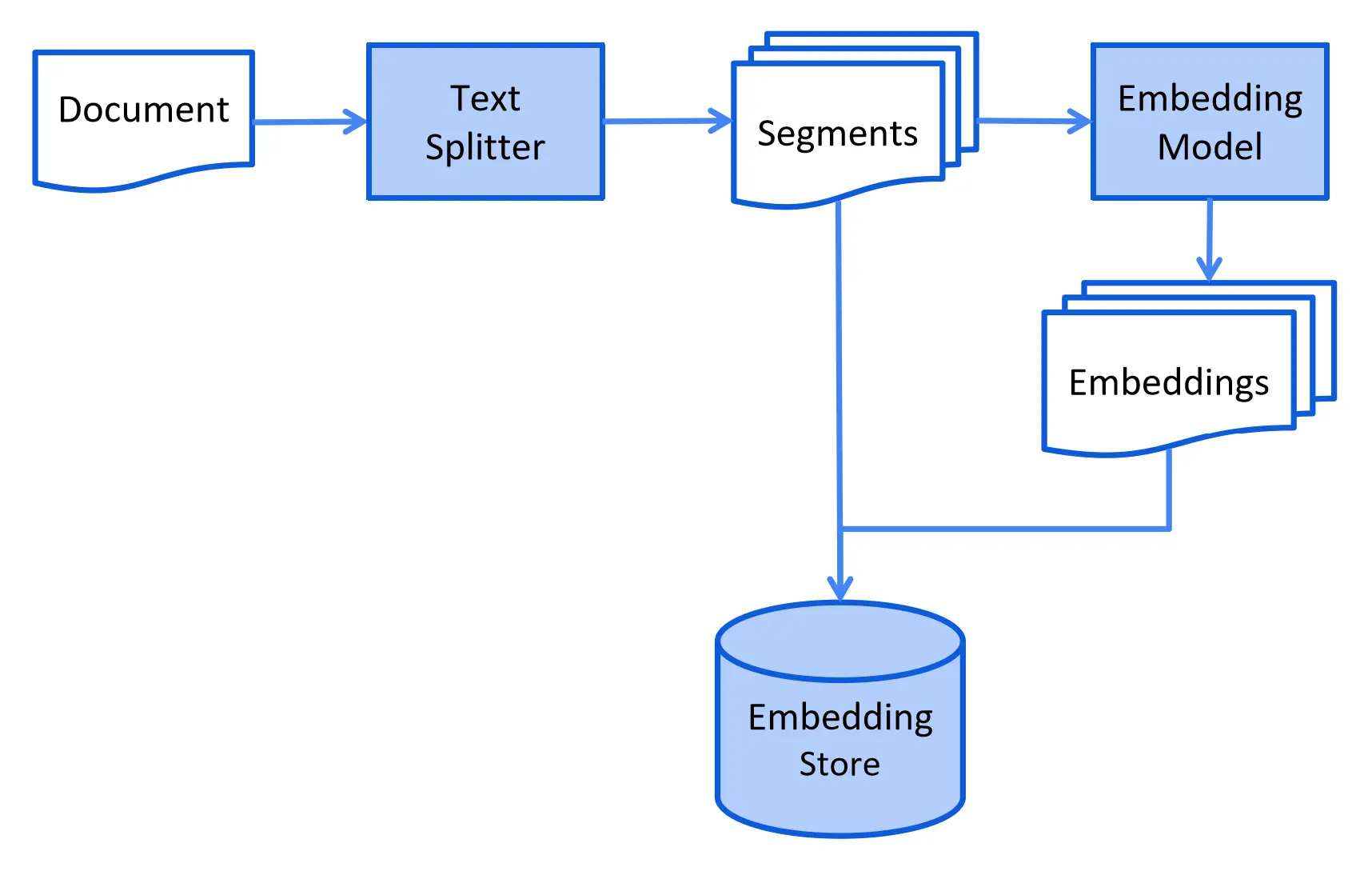
Let’s create a sample data file siva.txt in src/main/resources folder with the following content:
Siva, born on 25 June 1983, is a software architect working in India.
He started his career as a Java developer on 26 Oct 2006 and worked with other languages like Kotlin, Go, JavaScript, Python too.
He authored "Beginning Spring Boot 3" book with Apress Publishers.
He has also written "PrimeFaces Beginners Guide" and "Java Persistence with MyBatis 3" books with PacktPub.
Now we can load the data from the file and store the embeddings in the EmbeddingStore as follows:
URL fileUrl = RAGDemo.class.getResource("/siva.txt");
Path path = Paths.get(fileUrl.toURI());
Document document = FileSystemDocumentLoader.loadDocument(path, new TextDocumentParser());
DocumentSplitter splitter = DocumentSplitters.recursive(600, 0);
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
embeddingStore.addAll(embeddings, segments);
You can also use the EmbeddingStoreIngestor to ingest data into the EmbeddingStore as follows:
URL fileUrl = RAGDemo.class.getResource("/siva.txt");
Path path = Paths.get(fileUrl.toURI());
Document document = FileSystemDocumentLoader.loadDocument(path, new TextDocumentParser());
DocumentSplitter splitter = DocumentSplitters.recursive(600, 0);
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
Querying LLMs with data from EmbeddingStore
Once we have ingested data into the EmbeddingStore, we can query the EmbeddingStore using natural language and retrieve relevant data. Then, we can query the AI models passing along the relevant data to get the responses.
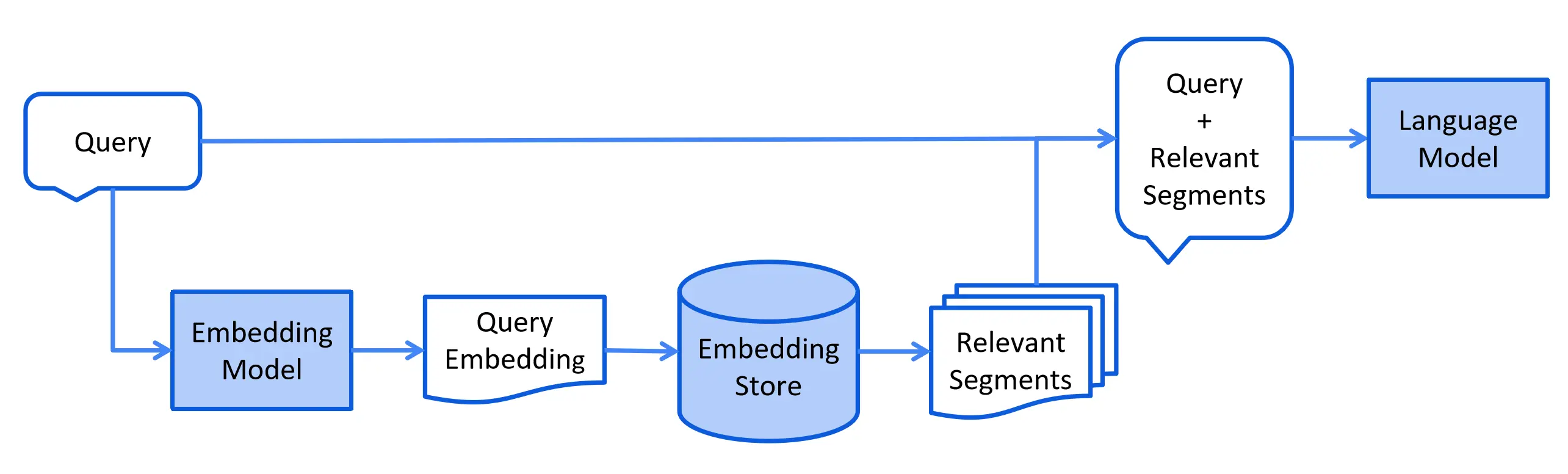
Embedding queryEmbedding = embeddingModel.embed("Tell me about Siva?").content();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.findRelevant(queryEmbedding, 1);
EmbeddingMatch<TextSegment> embeddingMatch = relevant.getFirst();
String information = embeddingMatch.embedded().text();
Prompt prompt = PromptTemplate.from("""
Tell me about {{name}}?
Use the following information to answer the question:
{{information}}
""").apply(Map.of("name", "Siva","information", information));
String answer = model.generate(prompt.toUserMessage()).content().text();
System.out.println("Answer:"+answer);
// Output:
// Answer:Siva is a software architect born on 25 June 1983 in India.
// He began his career as a Java developer on 26 Oct 2006 and has since worked with other languages
// such as Kotlin, Go, JavaScript, and Python. Siva has authored several books including
// "Beginning Spring Boot 3" with Apress Publishers, "PrimeFaces Beginners Guide" and
// "Java Persistence with MyBatis 3" with PacktPub.
WARNING
One thing to be mindful of is the length of the relevant data that will be passed to the AI models. The AI models might have a limit on the number of tokens they can process at a time. Also, the LLMs might charge you based on the number of tokens processed.
While this works, we can simplify this using AiServices with ContentRetriever as follows:
record Person(String name,
LocalDate dateOfBirth,
int experienceInYears,
List<String> books) {
}
interface PersonDataExtractor {
@UserMessage("Get information about {{it}} as of {{current_date}}")
Person getInfoAbout(String name);
}
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(1)
.build();
PersonDataExtractor extractor =
AiServices.builder(PersonDataExtractor.class)
.chatLanguageModel(model)
.contentRetriever(contentRetriever)
.build();
Person person = extractor.getInfoAbout("Siva");
System.out.println(person);
// Output:
// Person[name=Siva, dateOfBirth=1983-06-25, experienceInYears=17, books=[Beginning Spring Boot 3, PrimeFaces Beginners Guide, Java Persistence with MyBatis 3]]
We have created an instance of EmbeddingStoreContentRetriever and get an instance of PersonDataExtractor using AiServices by passing the ContentRetriever.
Now, when we can call the getInfoAbout() method, it will get the relevant data from the EmbeddingStore and pass it to the AI model to get the response.
Conclusion
In this article, we have seen how we can augment the LLM capabilities with our own data using RAG.
To learn more advanced RAG capabilities provided by LangChain4j, see https://docs.langchain4j.dev/tutorials/rag.
Related content
- My First Impression of Google's NotebookLM
- Spring AI RAG using Embedding Models and Vector Databases
- Getting Started with Spring AI and Open AI
- LangChain4j AiServices Tutorial
- Generative AI Conversations using LangChain4j ChatMemory